By Sparring With AlphaGo, Researchers Learn How an Algorithm Thinks





Even the smartest humans miss patterns that computers see instantly.
“The game is amazing. Crazy. Beautiful.”
Fan Hui is speaking to a chatty audience at the 2016 European Go Congress in St. Petersburg, Russia, gushing over a game of Go played by one of his mentors. Hui’s enthusiasm is infectious—the room’s chatter subsides as he pulls up slides of the complex Chinese game, whose players battle to dominate a 19×19 board with black and white tiles called stones. Hui’s mentor, AlphaGo, has studied strategies built over the game’s 4,000-year history, and has played thousands of practice matches. But a training regiment that took Hui years to perfect, AlphaGo did in about four weeks.
AlphaGo isn’t a more experienced player, or even a human at all; it’s a system of algorithms out of Alphabet DeepMind’s offices in London. The game Hui showed to the Saint Petersburg audience is one the machine played against itself, and to Hui, is an example of the beauty of AlphaGo’s strategic mind.
The perfect game
Even the smartest humans miss patterns computers see instantly. Problems like file-compression, translation and custom drug fabrication have millions of variables and data points whose limits exceed human understanding dozens of times over. By offloading the world’s complexities onto mechanical brains better suited for them, we might see what patterns humans have been missing for thousands of years.
For researchers, that means a new age of human progress is already upon us, but not necessarily driven by human ingenuity. Machines have already begun to outstrip human intellect and teach their creators about manmade constructs like games and language.
AlphaGo has become the new DeepBlue—an IBM algorithm that beat Gary Kasparov at chess in 1997. It shows the power of the mechanical minds we can create, and its development and triumph over both Hui and Go world champion Lee Sedol (and its fame as a mystery challenger in online Go games) has been well-chronicled. But since his initial tussle with AlphaGo one year ago this month, Hui has been playing against it nearly every day, to study how the software thinks.
Hui believes Go is the perfect game for this task. It’s endlessly complex—there are more possible game configurations than atoms in the universe—and by studying both the games they play against one another and the program’s matches with Sedol, Hui has been able to get inside AlphaGo’s mind. In turn, the software has earned his respect.
“AlphaGo is our partner to understanding the game of Go,” Hui says. “Humans, we’ve played for 4,000 years and maybe we understand 5 percent of this game.”
The black box
There are limits to what humans can learn about AlphaGo from combing through code. The way deep neural networks make decisions is often referred to as a “black box”—while researchers can tune knobs on the outside to vary how the machine functions, its inner workings are granular and difficult to decipher, making the process extremely arduous. For this reason, researchers have been trying to find other ways to interpret how the neural net processes information and understands ideas.
“The problem is that the knowledge gets baked into the network, rather than into us,” Google researcher Michael Tyka told Nature. “Have we really understood anything? Not really—the network has.”
Tyka was part of the Google team that first published work on DeepDream, a computer-vision experiment that went viral in 2015. The team trained a deep neural network to classify images, i.e. show the network a picture, it tells you what the image depicts. Except instead of asking it to look at pictures, they programmed the network to look at a word and produce what it thought would be an image that represents the word. The deep neural network would then supply its visual “idea” of different words.
And it worked. The team gave the network the word “banana,” for example, and it produced a dizzying fractal of banana-shaped objects. But the experiment also provided insight into how the machine thought about objects. When asked to produce dumbbells, the network generated gray dumbbell shapes with beige protrusions—arms. The neural net correlated arms and dumbbells so highly, they were seen as almost one object.
The machine obviously had an incorrect perception of what a dumbbell was; the researchers could either fix the data being used to teach the machine, or change how the machine processed that data. In the real world, this method could be used to, for instance, make sure self-driving cars don’t stop when they see bikes without people on them.
With this technique in mind, DeepMind can look at Hui’s games with AlphaGo to understand their own creation. When does the machine know it’s won? What has it learned outside of how a human would play the game? How does it prefer to play?
AlphaGo, the player
To characterize AlphaGo would be to compliment it. Hui calls it clever, strong, relentless, and above all, confident. This confidence is the most important part for Hui, and the most emblematic of a machine playing a human game.
“AlphaGo, as a program, can never fear something,” Hui says. “For humans, we can never do this. If you have confidence, it’s just for the moment.”
That confidence is crucial to AlphaGo’s strategy. In the 37th move of its matchup against Sedol, AlphaGo made a move so bold—Hui says beautiful—that Sedol left the room for nearly 15 minutes. Well before that, in the tournament’s first round, the computer made a move that is perhaps even more revealing of its nature.
Almost halfway through the first match, Lee and AlphaGo were struggling for dominance of the board’s left side. One stone placement after another found Sedol only able to match, but not outplay, AlphaGo. Then, AlphaGo completed move 77. Forced off the left side of the board, Sedol shook his head and left for a smoke break. From that point forward, AlphaGo didn’t play the same way. It stopped trying to widen its lead.
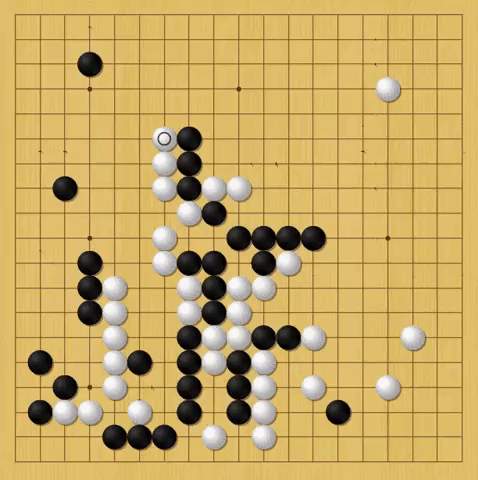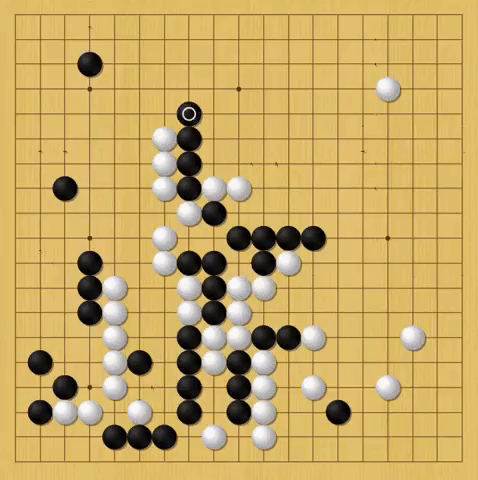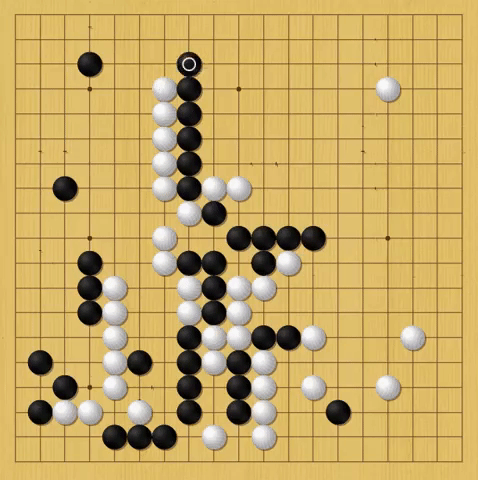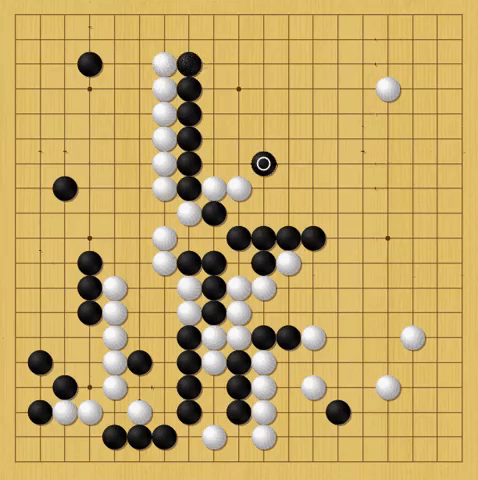
White: AlphaGo, Black: Sedol
AlphaGo calculates its win rate after every move, and Hui had played the machine enough to immediately understand what happened. At his estimation, once AlphaGo hits a 70 percent win rate, it starts to play as if it knows it’s going to win. Its moves become less aggressive and it takes fewer chances, focusing on maintaining a slight lead rather than potentially jeopardizing the win with high-risk high-reward moves. In notes about the match a few moves later, Hui wrote:
Seeing AlphaGo’s response at 80, I wrote down in my notebook:”Statement of victory!”
…I believe I know AlphaGo as well as anybody, and in my view a move like this is really a demonstration of its matchless confidence. AlphaGo does not pursue the biggest victory, only the most certain one. Once it has a lead of two or three points, AlphaGo is completely capable of holding it until the end.
Looking at AlphaGo’s 74% win rate confirmed my impressions.
Understanding what the algorithm is thinking is only the beginning—the next step is understanding why. Unraveling those mysteries could help researchers learn the cause-and-effect of their training data, and in turn how to manipulate that data to force different decisions. They could make AlphaGo seek the largest possible margin of victory, or generally play more or less aggressively. Applied to other areas of research—which DeepMind is not involved in, or at least not publicly—similar methods could be used to make a self-driving car’s programming more or less aggressive.
Machine teachers
Across the pond from DeepMind’s London facility, Sidd Srinivasa is in Pittsburgh, Pennsylvania, rethinking the car. Or rather, he’s taking notes while an algorithm does the thinking. Srinivasa is head of the Carnegie Mellon Personal Robotics Lab, and he operates around a shockingly simple proposition: Robots don’t need to work like humans.
Srinivasa heads to the University of Washington this fall after more than five years teaching at Carnegie Mellon, where his work has focused on letting robots decide how they want to interact with the world, including through their basic design. By learning to optimize motions, algorithms are teaching roboticists new ways of thinking about movement.
“What is the best hand to pick up an Oreo?” Srinivasa asks. “People say, ‘You should build five-finger robotic hands that have 42 joints in them that are tendon-driven.’ And I’m like, ‘Are you crazy? Everything will break all the time!’”
That’s why the Home Exploring Robotic Butler, or HERB, has three fingers on each of its two hands. At the CMU Robotics Lab, HERB is actually tasked with picking up and disassembling an Oreo, a delicate exercise for large metal hands. Instead of picking up the cookie with all three fingers along the edge, like a human, Herb found more success putting one finger one on each side of the cookie, and using a third to apply pressure to the back. That way, the Oreo wouldn’t fall out into the robot’s palm, where it was not dextrous enough to catch it.
Learning through this kind of trial and error—known in research circles as reinforcement learning—HERB was eventually able to complete the entire challenge. It picked up an Oreo, separated the two sides, and scraped off the cream filling. That might seem like a small challenge—with unclear rewards for a robot that can’t eat cookies—but it was one ultimately solved in a way humans might not have tried.
While HERB exists in the physical world, and AlphaGo in the virtual one, they each have lessons to teach. It’s not enough to understand how AI is built—we also need to study how they interact with the world to learn their motivations. Like everything else in science, experiments evolve outside of the lab. Artificial intelligence is no different.
“With AlphaGo, everything is changed, Hui says. “It’s like another door is opened for everyone.”
Mike Murphy contributed reporting.
NEXT STORY: China’s Artificial-Intelligence Boom