A Playbook for How Cities Should Share and Protect Data

Stephan Guarch/Shutterstock.com





A detailed guide from Harvard helps governments protect residents’ personal information in open-data initiatives.
For any city, open data is a double-edged sword; the most useful information can also be the most sensitive. To help officials balance the risks and benefits, researchers at Harvard University have created a playbook for open data, complete with best practices, examples of what has and hasn’t worked so far, and a thorough checklist of what to consider when embarking on a new data project.
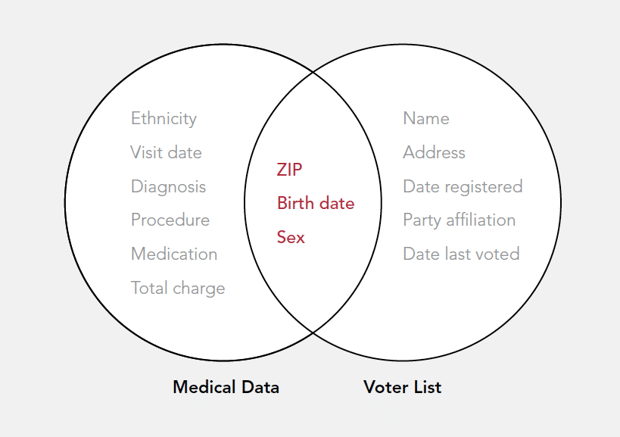
In the absence of clear-cut regulations, cities have always been somewhat haphazard about how they release data, and how they protect it. It’s not uncommon for officials to face public backlash after releasing seemingly innocuous data—transit information, for example—and finding out, only afterward, that combined with other datasets, there’s enough information to track individuals. Cyber security experts call this the mosaic effect, and it can undermine traditional data protection efforts like anonymizing data or removing certain identifiers.
Still, with advocates pushing for more open government at the local level, and with municipalities locked in a race to become truly smart cities, the trove of public data is only going to grow. Even the federal government isn’t immune to this challenge.
“In this new world of such rich data, often times it’s not [the threat] of someone getting data they shouldn't have access to, but being able to mine what’s already out there for information that shouldn’t have been stored,” says Ben Green, the report’s lead author and a graduate student at Harvard University’s Berkman Klein Center for Internet & Society.
The playbook makes four main recommendations for technology officers in the municipal government, and each is broken down into, as Green puts it, “here’s what you need to know, here’s what you need to do, and then here’s how you do it.”
Find the balance between risk and value: Zero risk is impossible, a point perhaps cities don’t acknowledge enough. But according to the researchers, the trick is to find a level of risk that officials and the public are willing to accept. That can be done by conducting thorough risk-benefit analysis before designing any data sharing program. That means sussing out the vulnerabilities, the potential threats and their likelihood of happening, the impact and the limits of traditional risk mitigation efforts. In determining the value, the key question to ask is who will use the data, who benefits from it, and how.
Consider privacy at each stage of the data lifecycle: That lifecycle includes data collection, maintenance, release and retirement—when unpublished data should be removed because it’s no longer relevant. It’s typical for cities to think about privacy only when data is about to be released, but Green says those concerns should be considered at the very first stage. That is to say, cities shouldn’t collect excessive data that isn’t relevant to the project and that could become a vulnerability in the future—for example, recording home addresses while surveying passersby.
Develop a structure for privacy management: ”The harder challenge is developing the internal and operational expertise, and valuing protecting privacy as an essential component of open data program,” Green says. Because there are few, often outdated, guidelines at the federal and state level, the rules of releasing data should at least be consistent at the city scale. The researchers call for cities to develop their own privacy standards and establish a formal process for releasing data.
Keep the public informed: Nearly 80 percent of Americans are concerned about government surveillance, according to Pew surveys cited in the report. So the researchers stress the need for cities to engage the public, to earn its support by showing how open data has benefited the city and gaining trust by being transparent about the entire process. When Chicago, for example, released data about the more than 100 million taxi trips, it also published a detailed post about how that data was prepared and altered to protect privacy—a step that the researchers write should be “common practice.”
Even with a hundred-plus pages of tips and guidelines, though, the playbook doesn’t answer the specifics. It won’t tell cities exactly which fields to remove from their published data, for example, or how large the geographic blocks should be when grouping data to protect people’s addresses. In part, it’s the result of the researchers’ own limitations, Green admits. The answers depend on the kind of data, and can require trial-and-error processes through complex computer modeling.
But also, “we don't want to be prescriptive and define a value that a city government and public should have,” he says. “We’re happy leaving decision-making power in the city's hand.”
You can read the full report here.